This is a quick note. There are plenty of other online resources
discussing the same topic. I want to list the steps in one place, so
it’s easier for anyone who wants to follow this practice.
In a typical software development life cycle, a project needs to be deployed to multiple environments. Mule project is no exception.
Mule project uses java property files and JVM environment variables to manage project deployment to multiple environments. This solution has several parts.
mule-app-qa.properties
mule-app-prod.properties
The property names are common in these files. The property values vary depends on the environment. For example, we may have two properties “db.host” and “db.port” define as something like:
mule-app-dev.properties:
db.host=localhost
db.port=1001
mule-app-test.properties
db.host=testdb.mycompany.com
db.host=3069
<logger message=“port=${db.port}” level=“INFO” doc:name=“logger”/>
An environment variable is defined, for example, “env=dev” that allows the server to determine which environment the application is being deployed to, and therefore pick up the proper property files at runtime for the target platform.
This “-M-D” is a special way for Mule to pass properties to the JVM that runs Mule engine.
If your Mule ESB is configured as service, you can locate the startup script and add “-M-Denv=xxx” for each environment.
3. With Cloudhub, when you deploy the application, you choose which environment to deploy to, then on the deployment page, there is a “properties” tab next to “runtime”. From there, you can simply set the “env” property, for example, to “env=prod”.
This line will automatically become one of the following files depends on the ${env} setting:
<context:property-placeholder location="mmule-app-dev.properties" />
<context:property-placeholder location="mule-app-test.properties" />
<context:property-placeholder location="mule-app-prod.properties"/>
With this setup, the developer doesn’t have to worry about which environment the application will be deployed to. The source code stays exactly the same for all environment. The admin who deploys the application decides which target environment to deploy the application to.
In a typical software development life cycle, a project needs to be deployed to multiple environments. Mule project is no exception.
Mule project uses java property files and JVM environment variables to manage project deployment to multiple environments. This solution has several parts.
- Property files are created for each environment to store target specific parameters, typical file names are like
mule-app-qa.properties
mule-app-prod.properties
The property names are common in these files. The property values vary depends on the environment. For example, we may have two properties “db.host” and “db.port” define as something like:
mule-app-dev.properties:
db.host=localhost
db.port=1001
mule-app-test.properties
db.host=testdb.mycompany.com
db.host=3069
- In the source code the property will simply be referenced like:
<logger message=“port=${db.port}” level=“INFO” doc:name=“logger”/>
An environment variable is defined, for example, “env=dev” that allows the server to determine which environment the application is being deployed to, and therefore pick up the proper property files at runtime for the target platform.
- With Anypoint Studio, this is often defined inside mule-app.properties
- With on-prem server, it can be defined on the server start up command line like
This “-M-D” is a special way for Mule to pass properties to the JVM that runs Mule engine.
If your Mule ESB is configured as service, you can locate the startup script and add “-M-Denv=xxx” for each environment.
3. With Cloudhub, when you deploy the application, you choose which environment to deploy to, then on the deployment page, there is a “properties” tab next to “runtime”. From there, you can simply set the “env” property, for example, to “env=prod”.
- In a Mule/Flow configuration file (normally it’s in a common global config file), the property files are referenced as
This line will automatically become one of the following files depends on the ${env} setting:
<context:property-placeholder location="mmule-app-dev.properties" />
<context:property-placeholder location="mule-app-test.properties" />
<context:property-placeholder location="mule-app-prod.properties"/>
With this setup, the developer doesn’t have to worry about which environment the application will be deployed to. The source code stays exactly the same for all environment. The admin who deploys the application decides which target environment to deploy the application to.










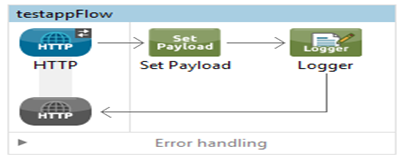

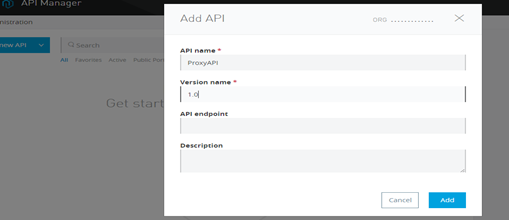
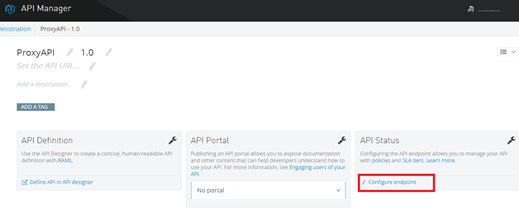
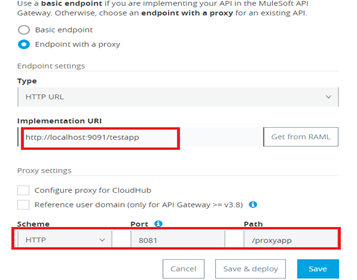
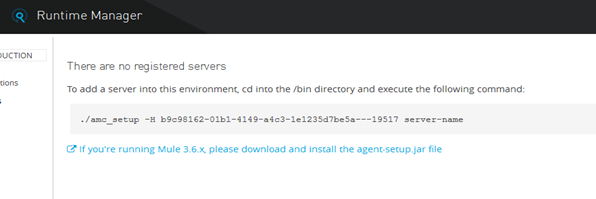
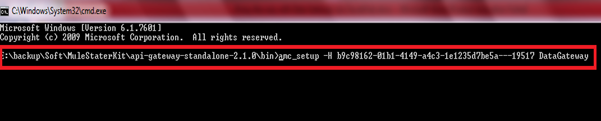
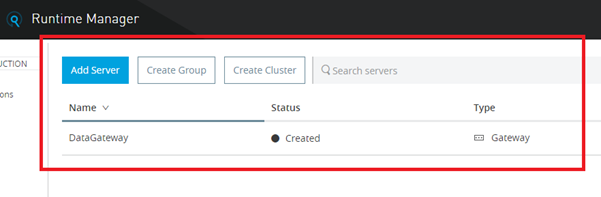
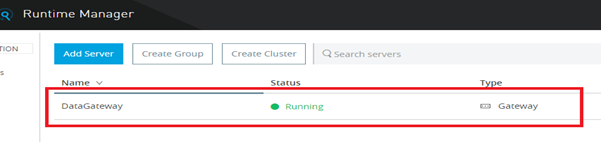
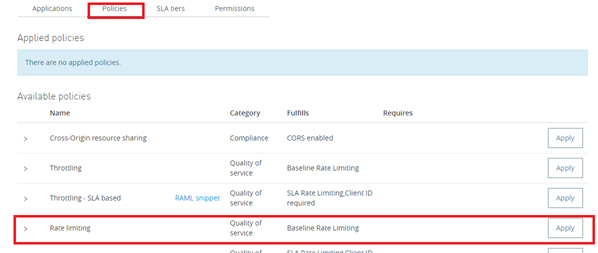

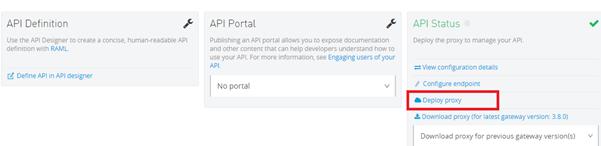
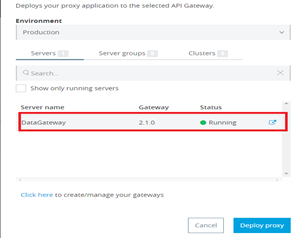
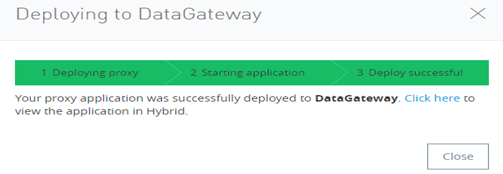

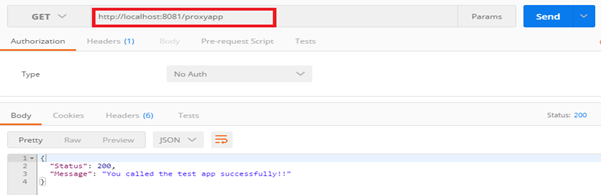
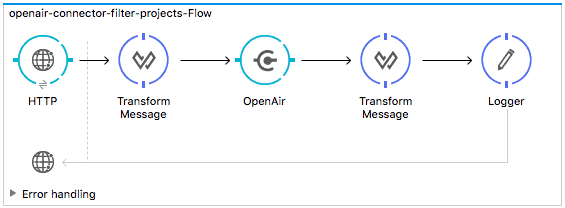
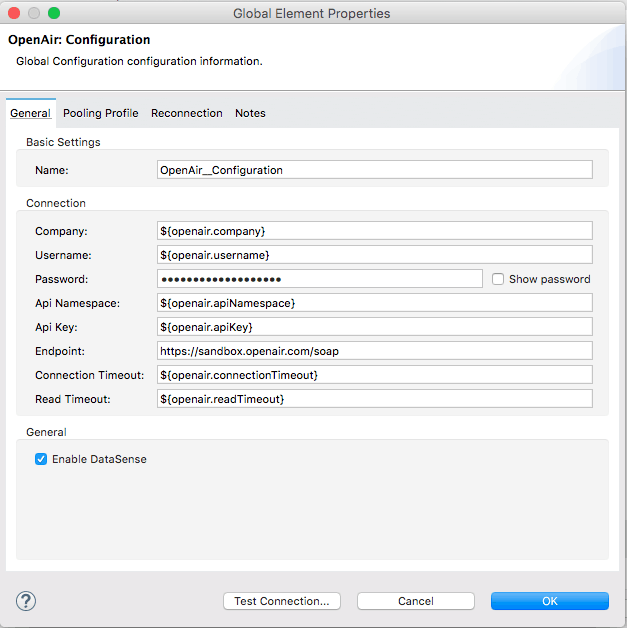
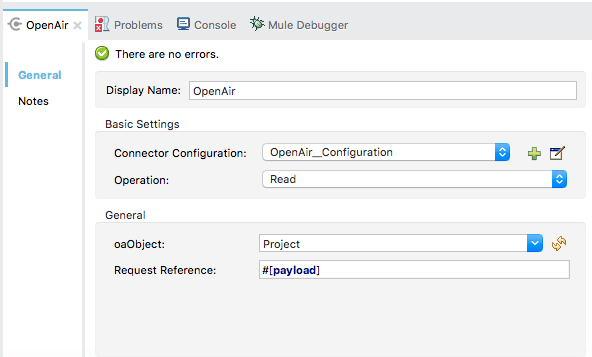



 Designing the Mule Flow With Anypoint Studio
Designing the Mule Flow With Anypoint Studio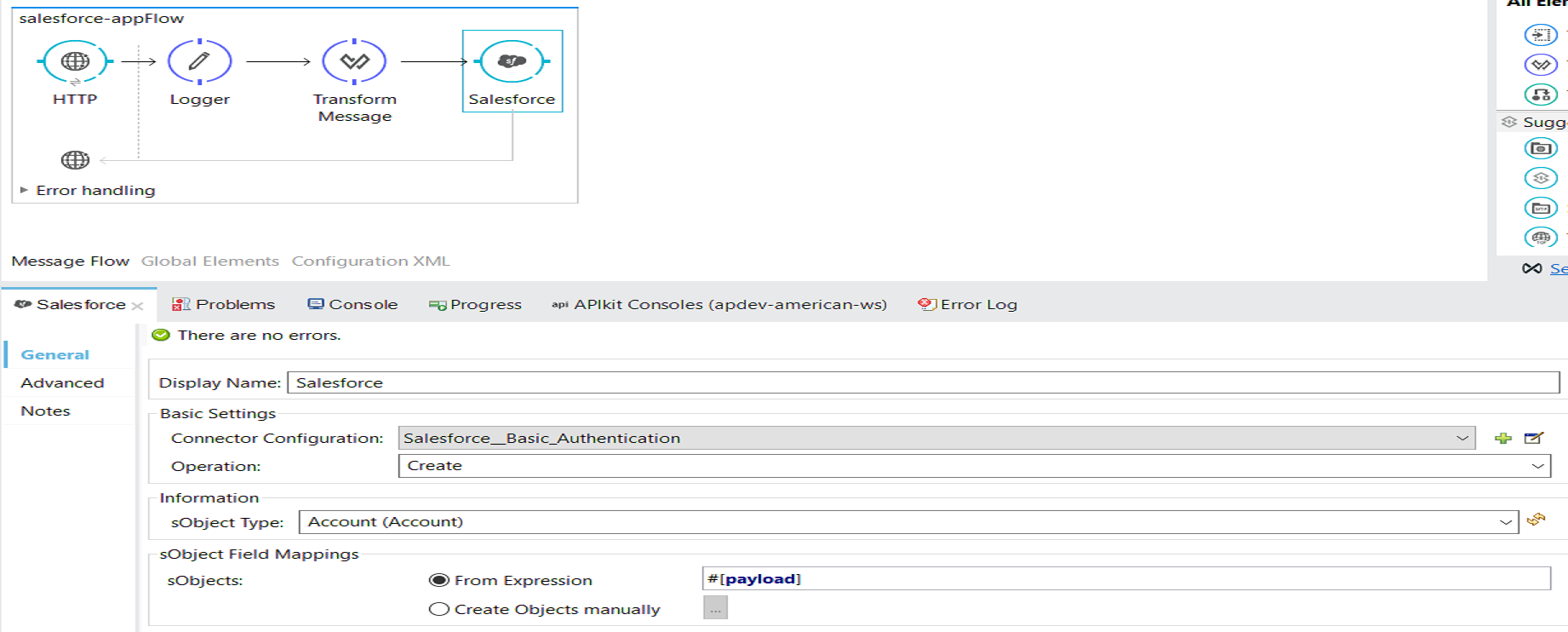
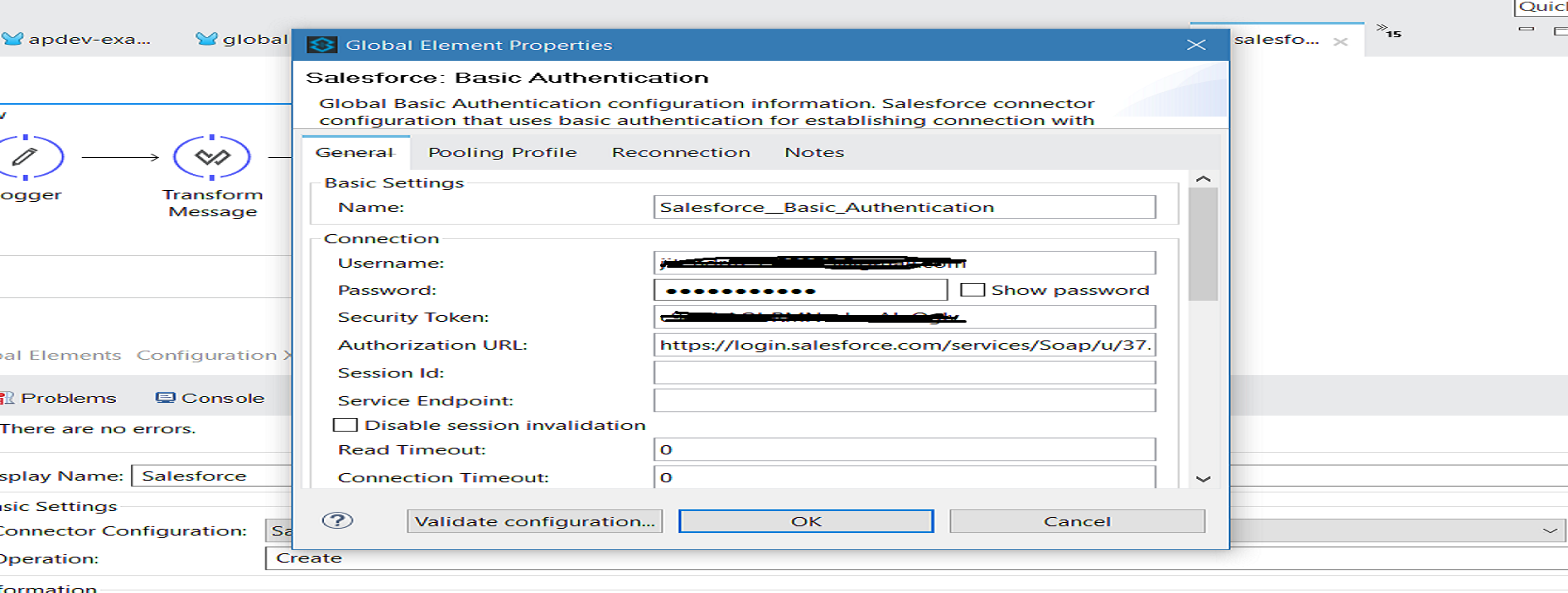
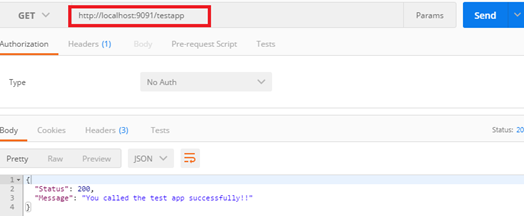
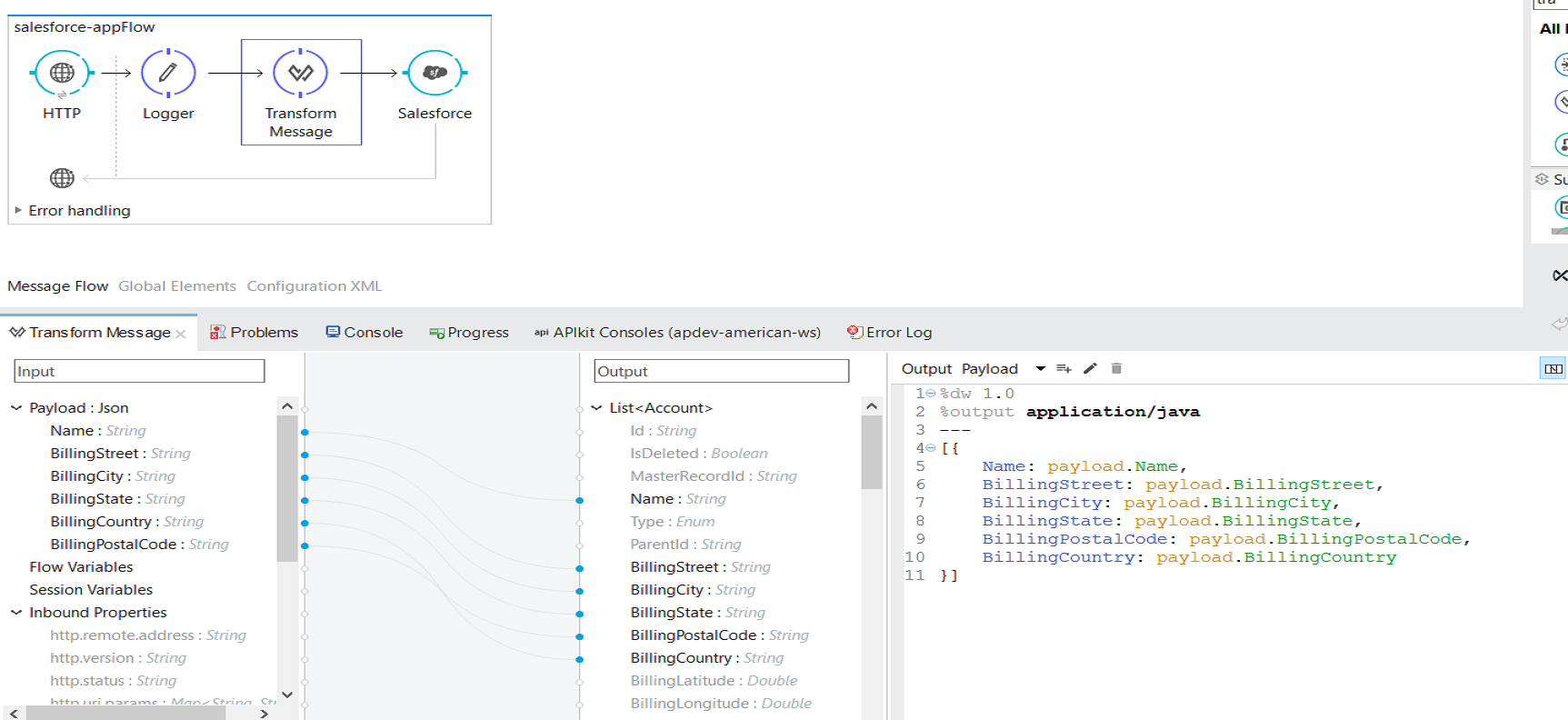 Input JSON example:
Input JSON example: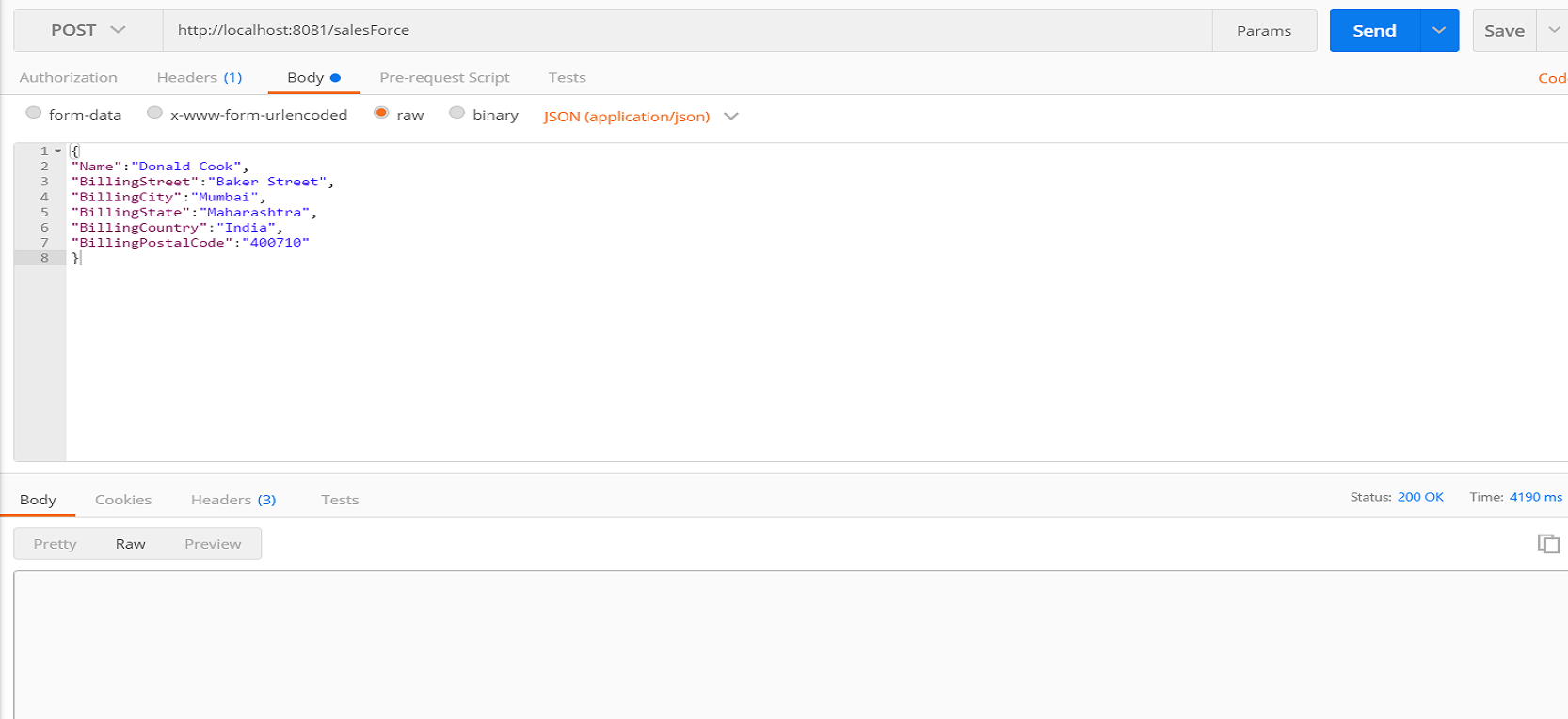
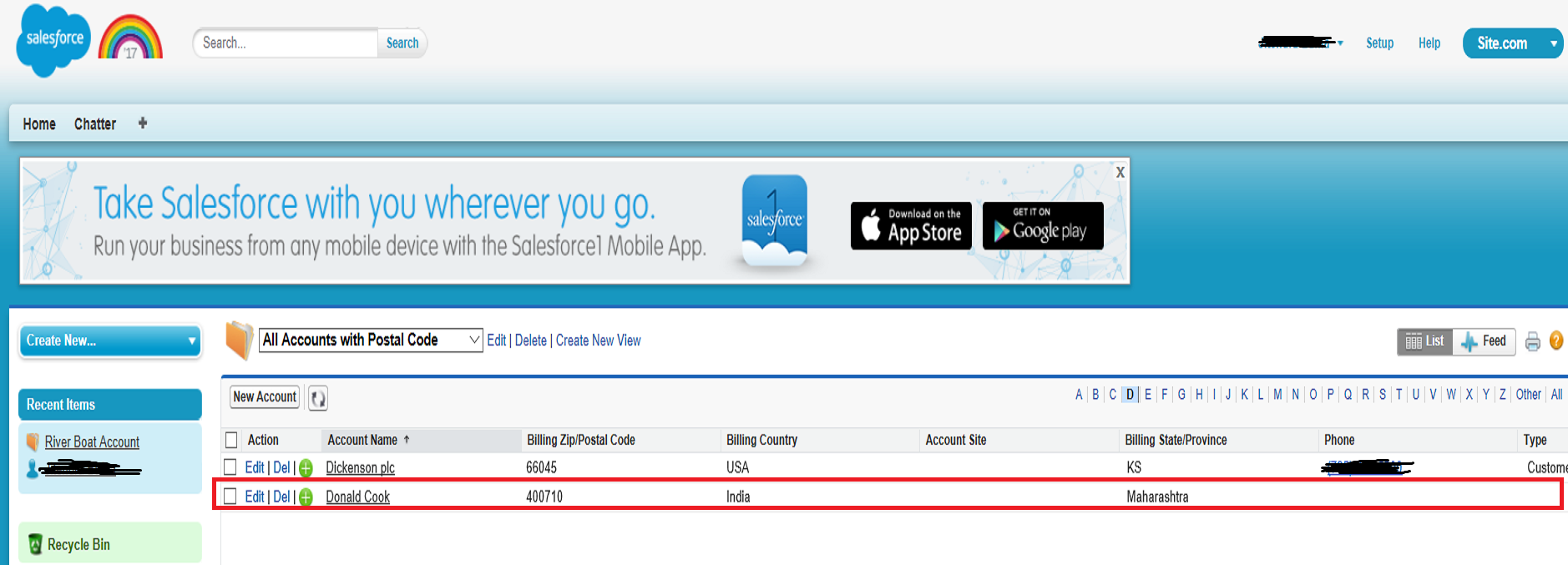
{kind=link}